如果你正在做 Agent 产品,最近一个很现实的问题一定绕不过去:
怎么在智能水平和调用成本之间,找到一个真正能落地的平衡点?
Anthropic 在最新这篇文章里,给出了一个很值得关注的答案,叫 Advisor Strategy。
简单说,就是:
让 Sonnet 或 Haiku 负责真正执行任务,让 Opus 只在关键决策点出来“当参谋”。
这样做的结果是,你不需要在整个任务过程中都付出 Opus 的高成本,却依然能在很多复杂场景里拿到接近 Opus 级别的判断质量。
Anthropic 也顺手把这个思路做成了 Claude Platform 里的一个新能力,叫 advisor tool。对开发者来说,这基本上意味着一件事:
原来需要自己手搓的一套“高级模型做决策、便宜模型做执行”的机制,现在可以更低成本、更标准化地接进 API。
一、什么是 Advisor Strategy?
先说结论版:
- Sonnet / Haiku = executor(执行者)
- Opus = advisor(顾问/参谋)
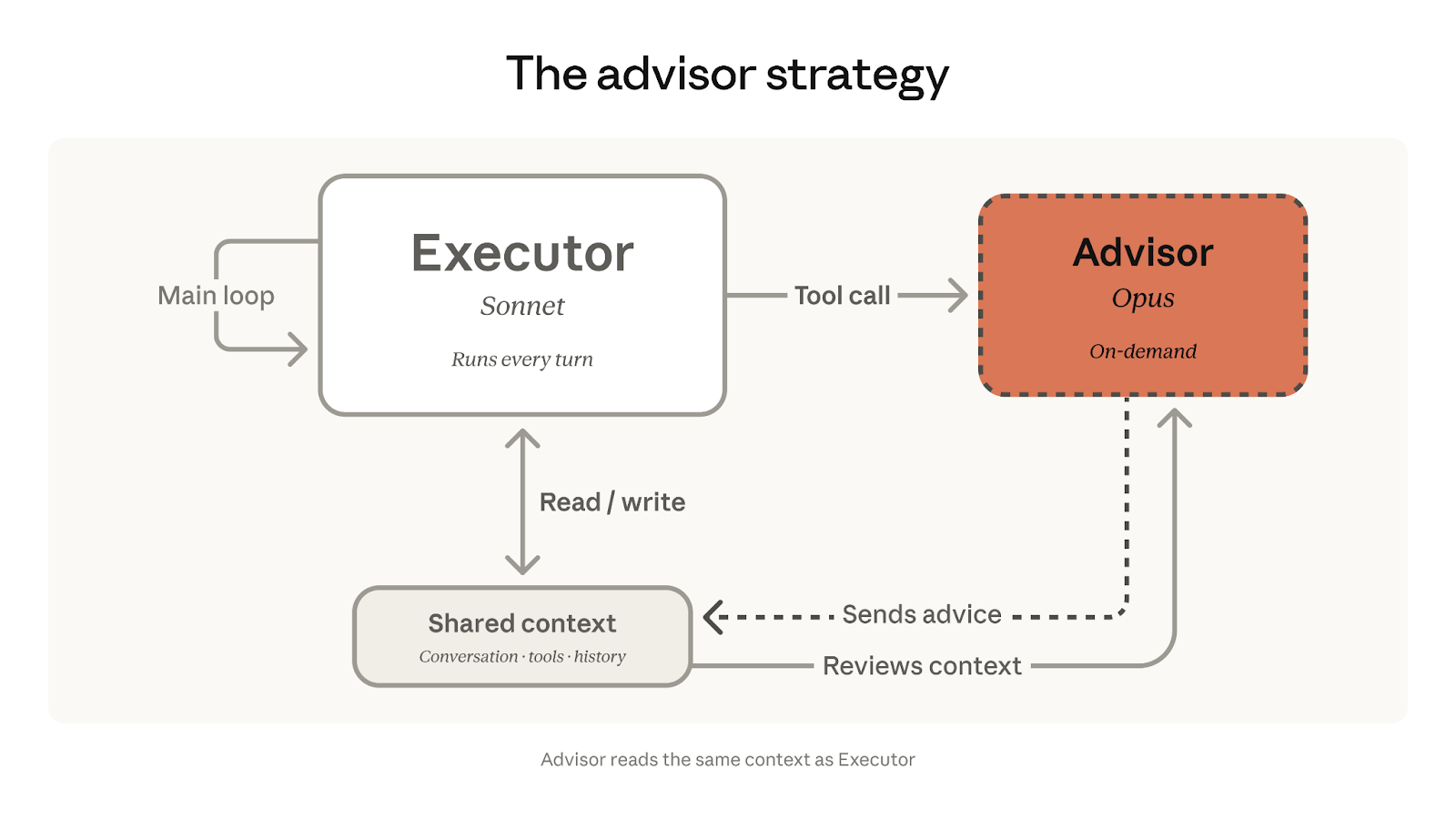
在这个架构里,执行者负责把任务从头跑到尾,包括:
- 调用工具
- 读取结果
- 继续迭代
- 完成最终输出
而 Advisor,也就是 Opus,不直接做这些事情。它的职责更像一个只在关键节点出现的高级顾问:
- 当执行者遇到难判断的问题时,向 Opus 咨询
- Opus 基于共享上下文,返回一个建议
- 建议可能是一个计划、一个纠偏意见,或者一个“这里该停”的信号
- 然后执行者继续往下跑
这里最重要的一点是:
Advisor 不负责调用工具,也不直接给最终用户输出内容。它只负责给执行模型“出主意”。
这和很多人熟悉的多 Agent / 子 Agent 架构很不一样。
过去常见的模式是:
- 一个更强的大模型做总控
- 它拆任务
- 它分发给多个更小的 worker
- 再把结果汇总
而 Advisor Strategy 反过来了。
它不是“大脑统一调度一堆小兵”,而是:
让一个更便宜、更轻量的模型一路主导执行,只有在真正需要高阶推理的时候,才把问题递给更强的模型。
这意味着你不需要额外做:
- 复杂的任务拆解
- worker 池管理
- 编排逻辑
- 多轮上下文搬运
在很多 Agent 任务里,这会让系统设计明显更简单。
二、为什么这个策略值得重视?
因为它抓住了一个 Agent 时代很核心的现实:
不是所有 token 都值得用最贵的模型去生成。
一个完整的 Agent 任务里,真正需要最强推理能力的,往往只占少数关键节点。比如:
- 选哪条路径继续
- 某个修复方向对不对
- 这里要不要停止尝试
- 两个方案的结构性优劣是什么
而大量的执行成本,其实花在这些环节:
- 工具调用
- 结果读取
- 中间状态整理
- 重复试错
- 最终产出组织
如果这些步骤全部都由 Opus 来做,当然很强,但也会很贵。
Advisor Strategy 的本质,就是把钱花在真正该花的地方:
让高智力模型只负责高杠杆决策,让性价比更高的模型负责执行过程。
这不只是“便宜一点”,而是更像一种系统层面的成本优化。
三、Anthropic 给出的效果数据
Anthropic 在文中给出了一些很有意思的评估结果。
1)Sonnet + Opus Advisor
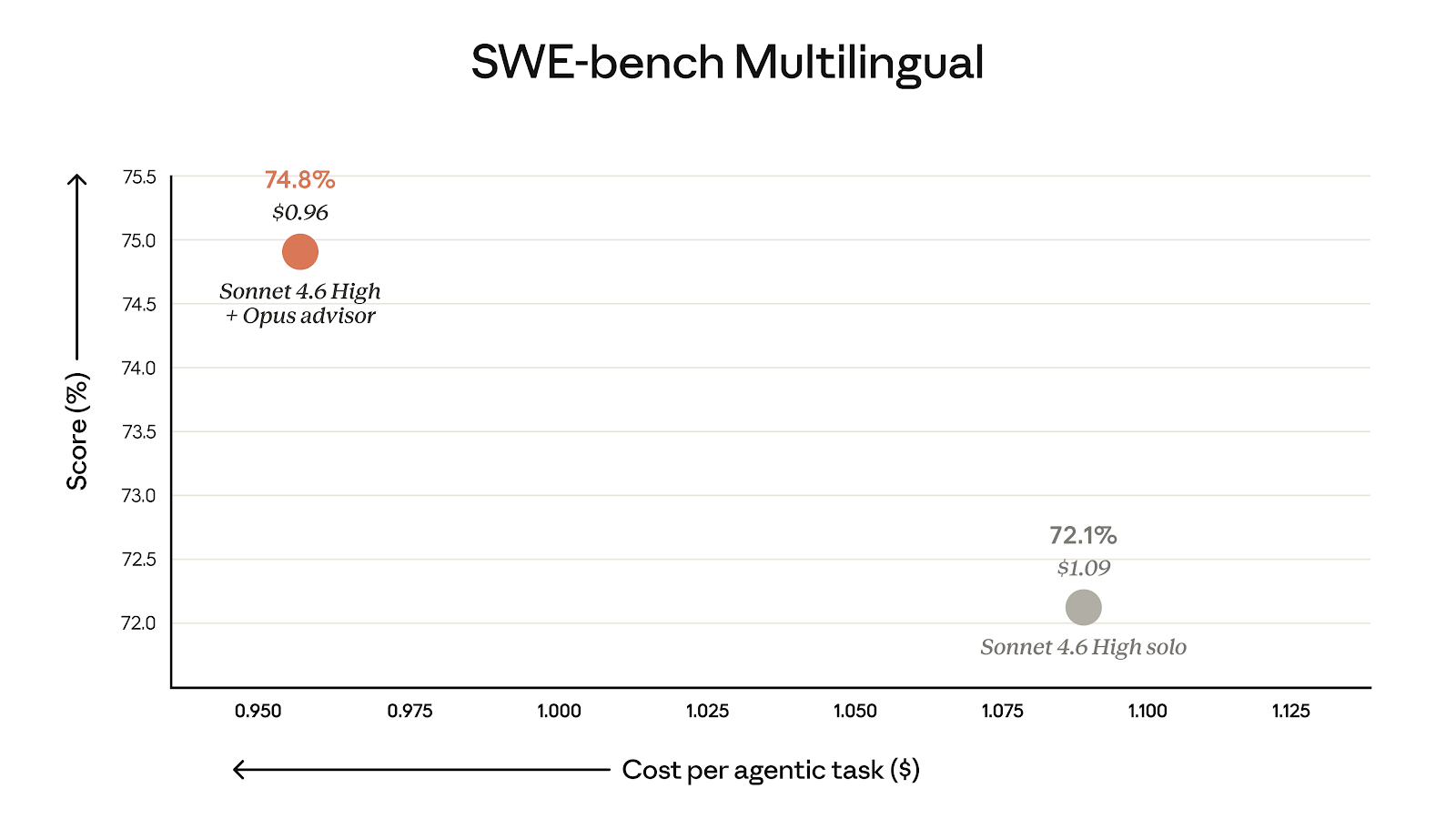
在 SWE-bench Multilingual 上:
- 相比 Sonnet 单独运行
- Sonnet + Opus Advisor 的成绩提升了 2.7 个百分点
- 同时,每个 agentic task 的成本还降低了 11.9%
这件事很有含金量。
因为它不是“多花一点钱,换更好结果”,而是:
结果更好,成本反而更低。
文中还提到,在 BrowseComp 和 Terminal-Bench 2.0 上,带 Opus Advisor 的 Sonnet 也有更好的分数表现,并且单任务成本低于 Sonnet 单跑。
2)Haiku + Opus Advisor
这个组合更适合高并发、对成本极度敏感的场景。
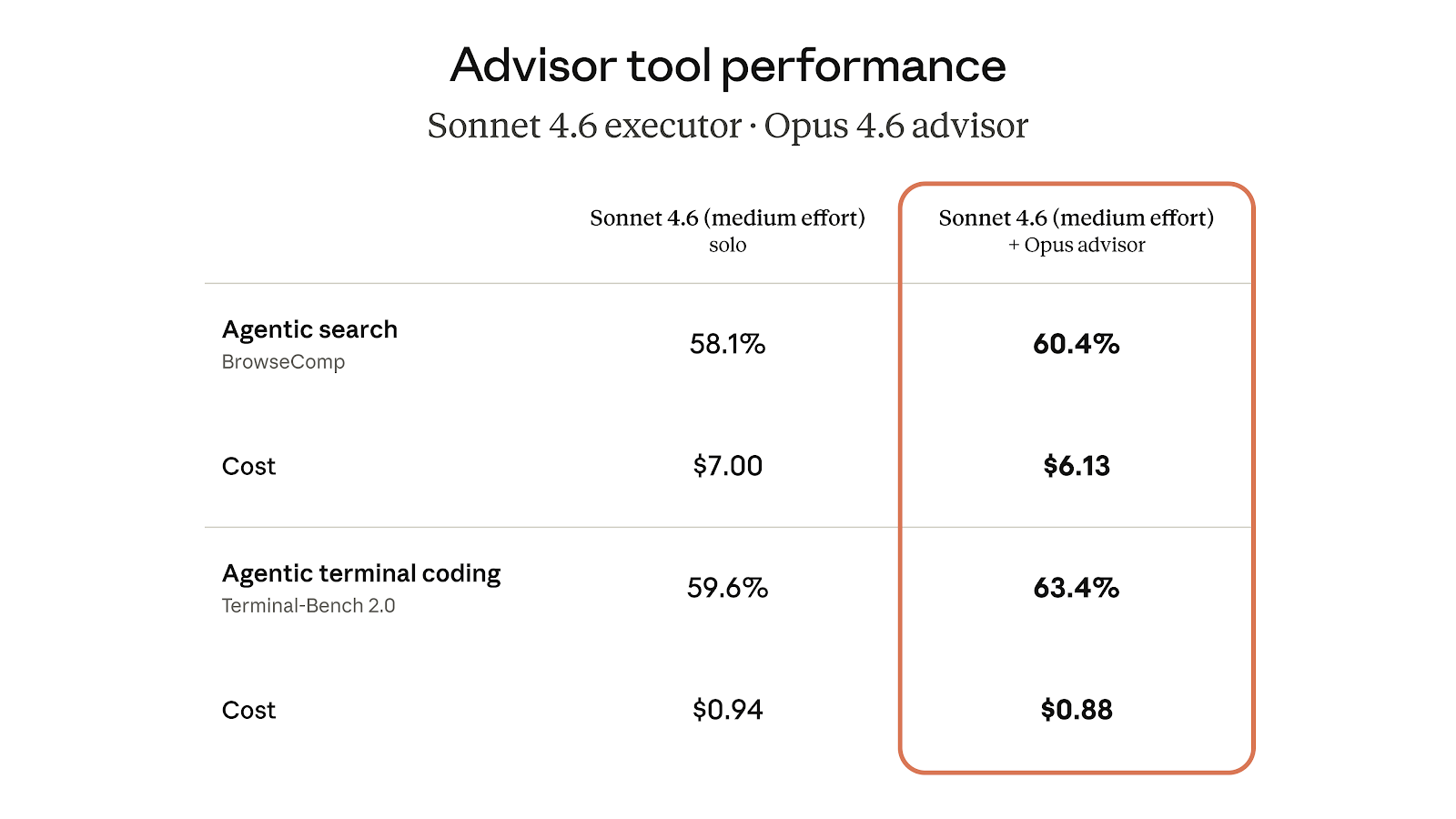
在 BrowseComp 上:
- Haiku 单独运行:19.7%
- Haiku + Opus Advisor:41.2%
也就是说,分数直接翻倍还多。
当然,它和 Sonnet 单跑相比,分数仍然落后 29%。但关键在成本:
- Haiku + Opus Advisor 每个任务的成本,比 Sonnet 单跑低 85%
这就非常适合一些量大、但又不能完全接受“纯便宜模型”效果的业务场景。
换句话说:
- 如果你想在效果上尽量接近前沿模型,但预算没那么紧,Sonnet + Opus Advisor 很有吸引力
- 如果你更看重吞吐量和成本,Haiku + Opus Advisor 可能是一条非常实用的路线
四、advisor tool 到底解决了什么问题?
真正让这件事从“一个不错的架构思路”变成“开发者会用”的关键,在于 Anthropic 把它做成了 advisor tool。
这个工具是服务端工具,Sonnet 和 Haiku 可以在需要的时候主动调用。
也就是说,开发者不需要自己再去手动编排:
- 什么时候升级到 Opus
- 怎么把上下文裁剪后传过去
- 拿到建议以后怎么回流给原模型
- 怎么处理多轮模型切换带来的额外请求
Anthropic 直接把这套切换放进了同一个 /v1/messages 请求里。
官方给出的调用方式大致是这样:
response = client.messages.create(
model="claude-sonnet-4-6", # executor
tools=[
{
"type": "advisor_20260301",
"name": "advisor",
"model": "claude-opus-4-6",
"max_uses": 3,
},
# ... your other tools
],
messages=[...]
)几个关键信息值得注意:
1)它是单请求内完成的
模型切换发生在同一个 Messages API 请求内部,不需要你额外发起多次 round-trip。
这意味着:
- 延迟更可控
- 工程复杂度更低
- 上下文管理更省心
2)是否调用 advisor,由 executor 自己决定
不是开发者硬编码“每一步都去问 Opus”,而是执行模型在需要时再调用。
这种设计非常重要,因为它避免了“为了用而用”的过度咨询。
3)可以设置成本上限
通过 max_uses,你可以限制一次请求里最多咨询 advisor 几次。
这让它在生产环境里更可控,不容易被复杂任务把成本无限拉高。
4)计费是分层统计的
Advisor 的 token 按 advisor 模型价格计费,executor 的 token 按 executor 模型计费。
官方提到,advisor 一次通常只生成一个较短的方案,通常在 400 到 700 个文本 token 左右,而真正长篇的执行和输出仍然由更便宜的 executor 完成。
所以整体成本仍然明显低于直接全程跑 Opus。
五、为什么它比“自己做一个 planning tool”更有吸引力?
文中引用了几家公司的反馈,这部分其实很值得产品和工程团队细看。
Bolt 的说法
它在复杂任务上的架构决策明显更好,而在简单任务上又几乎没有额外负担。整个规划路径和执行轨迹,完全不是一个量级。
Genspark 的说法
我们看到了 agent turns、tool calls 和整体分数的明显提升,效果比我们自己做的 planning tool 还要更好。
Eve Legal 的说法
在结构化文档抽取任务中,advisor tool 让 Haiku 4.5 能根据复杂度动态地调用 Opus 4.6 的智能,从而以 5 倍更低的成本,达到接近前沿模型的质量。
这些反馈透露出一个现实:
很多团队不是没想到“加一个规划层”,而是自己实现这件事的工程代价、策略复杂度和调优成本都不低。
如果底层平台把这件事标准化了,开发团队就可以把精力更多放在任务设计、工具设计和评估体系上,而不是反复手写模型编排。
六、它适合哪些场景?
如果把这篇文章翻译成一句更实用的话,我会这么总结:
凡是“执行过程很长,但真正高难判断只发生在少数关键节点”的 Agent 任务,都值得尝试 Advisor Strategy。
比如:
- 编码 Agent
- 浏览器自动化 Agent
- 终端操作 Agent
- 文档分析和信息抽取 Agent
- 高并发但有一定质量要求的批处理任务
尤其适合下面两类团队:
第一类,已经在用 Sonnet,但觉得成本还可以继续优化
这时候你不是要全盘换掉主模型,而是希望:
- 保住现在的执行稳定性
- 在复杂决策上补一点更强的判断
- 同时别把每个任务都抬到 Opus 的价格带
那 Sonnet + Opus Advisor 是非常自然的升级路径。
第二类,想用 Haiku 打高吞吐,但又怕质量不够
如果你的任务量很大,Sonnet 可能已经偏贵,纯 Haiku 又不太放心。
那么 Haiku + Opus Advisor 就像是一个“带安全气囊的低成本方案”。
它未必达到 Sonnet 的整体表现,但在很多量产场景里,性价比可能非常高。
七、怎么开始用?
Anthropic 目前把 advisor tool 作为 Claude Platform 上的 beta 能力提供。
开始使用需要做三件事:
- 添加 beta header:
anthropic-beta: advisor-tool-2026-03-01 - 在 Messages API 请求里加入
advisor_20260301 - 按照你的场景调整 system prompt
Anthropic 也建议你不要拍脑袋上线,而是把现有评测跑一遍,至少对比三种配置:
- Sonnet 单跑
- Sonnet 作为 executor + Opus 作为 advisor
- Opus 单跑
这个建议非常对。
因为 Advisor Strategy 是否划算,本质上不是一个“理念问题”,而是一个任务分布问题。
如果你的任务几乎每一步都需要顶级推理,那 advisor 带来的成本优势可能就没那么明显。
但如果你的任务里,真正难的部分只占少数关键节点,那么这个策略就很可能非常值。
八、最后聊一句,这背后其实是一种新的 Agent 设计思路
我觉得这篇文章真正值得关注的,不只是 Anthropic 又上了一个新 tool,而是它在传递一种越来越清晰的 Agent 产品思路:
未来的高质量 Agent,不一定是“全程用最强模型”,而更可能是“把最强模型放在最关键的位置上”。
这是一种更工程化、也更接近大规模生产的思路。
因为现实世界里的 Agent,不只是要聪明,还要:
- 可控
- 可扩展
- 可评估
- 成本能打
从这个角度看,Advisor Strategy 其实很像给 Agent 系统补上了一层“按需升级智能”的机制。
它不是简单地换一个更强模型,而是在系统层面做智能分层。
这件事,可能会比很多单纯的模型参数升级,更影响接下来一年 Agent 产品的实际落地方式。
原文信息
- 原文标题:The advisor strategy: Give agents an intelligence boost
- 来源:Anthropic
- 发布时间:2026 年 4 月 9 日
- 原文链接:https://claude.com/blog/the-advisor-strategy
附:文中提到的几个关键数据
- Sonnet + Opus Advisor 在 SWE-bench Multilingual 上,相比 Sonnet 单跑,分数提升 2.7 个百分点
- 同时,每个 agentic task 成本下降 11.9%
- Haiku + Opus Advisor 在 BrowseComp 上达到 41.2%
- Haiku 单跑在 BrowseComp 上为 19.7%
- Haiku + Opus Advisor 相比 Sonnet 单跑,成本低 85%
如果你正在做 Agent 产品,我会建议认真评估一下这个模式。
它不一定适合所有任务,但很可能会成为接下来一类 Agent 系统的标准配置。
Comments
0 public responses
All visitors can read comments. Sign in to join the discussion.
Log in to comment